Artificial Intelligence (AI) and Machine Learning (ML) Tech Talks
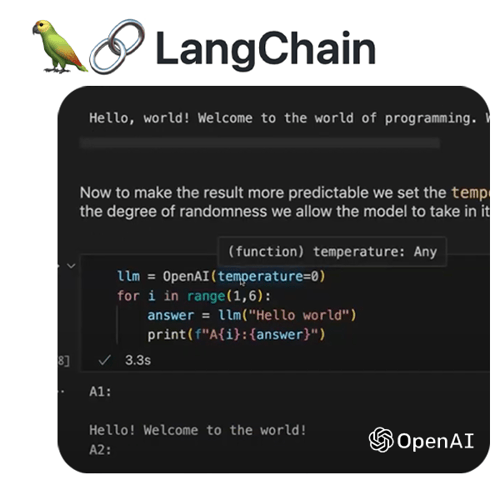
Developers and DevOps professionals, meet us at the Pulumi HQ to learn how to develop generative AI/ML applications using the Langchain Python library. Together, we will walk through the foundational concepts of the new generative domain, highlighting dev, sec, and ops along the way.
Join us at our Seattle office to take advantage of this chance to network with fellow developers, learn about the latest AI/ML trends, and boost your skills.
Food provided by Pulumi. Drinks provided by Tessell.